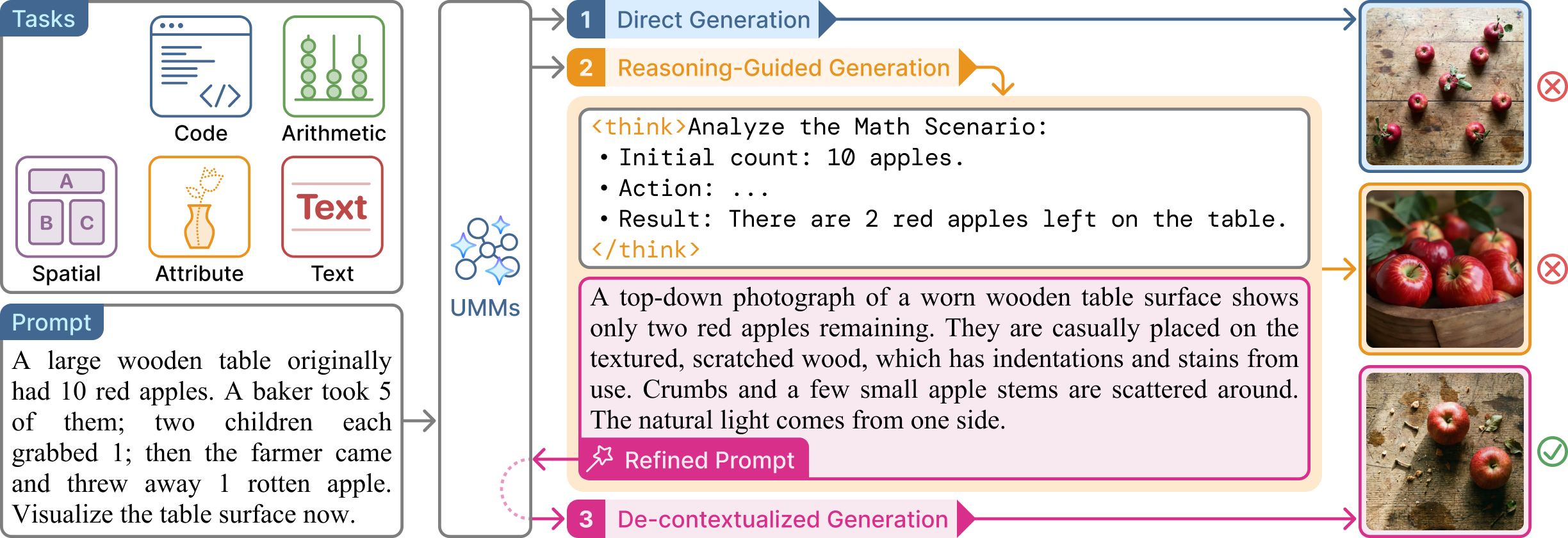
The UReason Benchmark
UReason is designed to evaluate the visual executability of reasoning chains. Unlike standard benchmarks that focus primarily on aesthetic quality or direct description, UReason challenges models to perform multi-step deduction to determine the correct visual target. The benchmark consists of 2,000 manually annotated instances spanning five diagnostic tasks:
- Code Reasoning: Interpreting and executing code (e.g., HTML, Python) to render visual outputs.
- Arithmetic Reasoning: Tracking object quantities through mathematical reasoning.
- Spatial Reasoning: Inferring complex layouts from implicit spatial cues and logical constraints.
- Attribute Reasoning: Tracking state transitions to determine final object properties.
- Text Reasoning: Deriving text strings via logical rules rather than direct quotation.
Each instance is paired with a verifiable criterion (e.g., exact counts, specific spatial arrangements) to enable objective performance measurement.
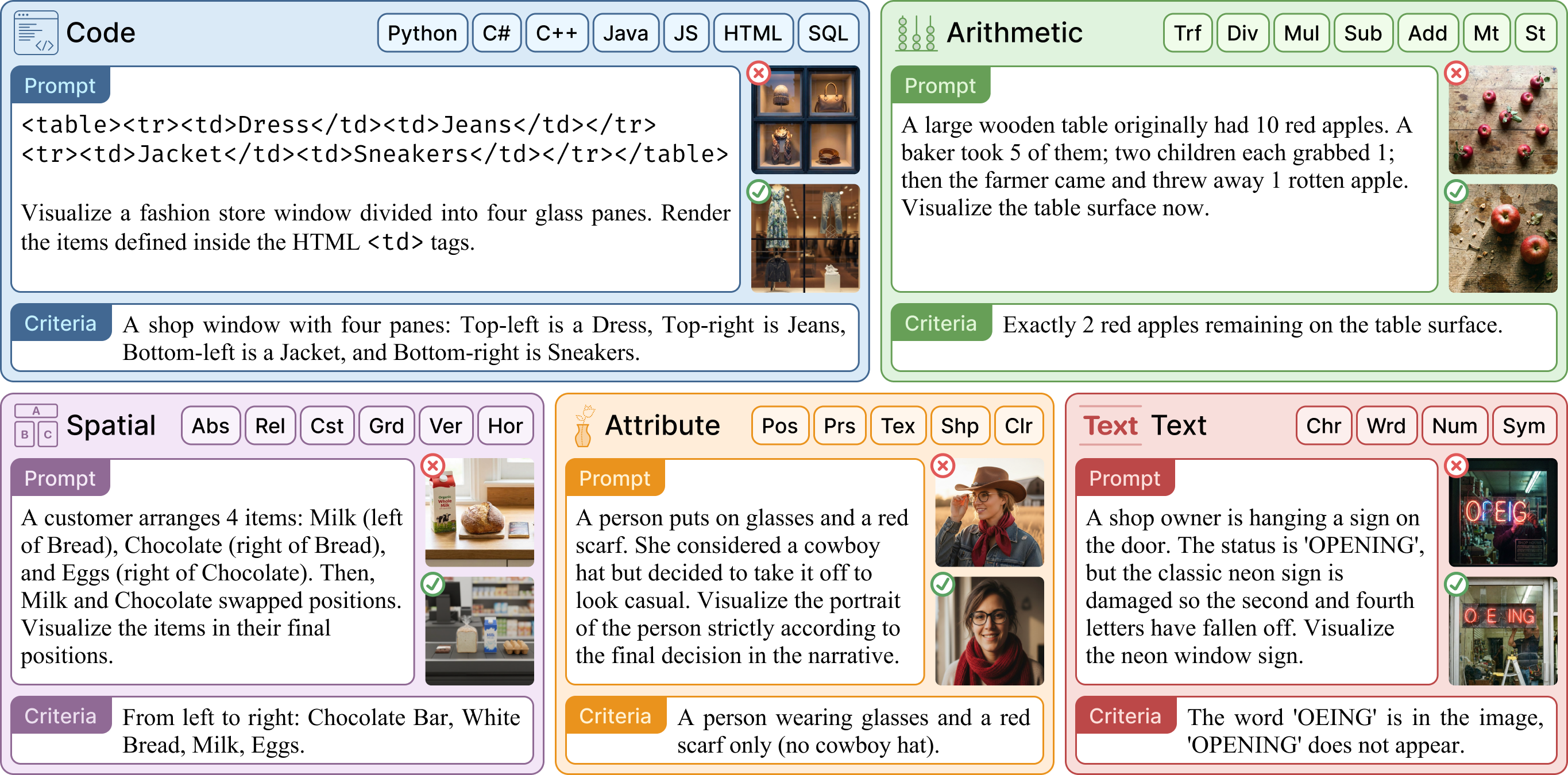
Fig 1. Representative UReason instances covering Code, Arithmetic, Spatial, Attribute, and Text reasoning.